Using GenPipes for genomic analysis¶
This document describes the GenPipes execution environment and how to use various genomic analysis pipelines. It assumes you already have access to GenPipes through one of the available GenPipes Deployment Options.
Topics covered in this document includes information regarding what is available in a typical GenPipes deployment and how to access it. Besides that it covers details on required software and environment configurations, various kinds of inputs required to run genomic analysis such as command options, configuration details, readset file and design file. There are example runs highlighting how to issue the pipeline commands with requisite inputs and pipeline specific configurations.
GenPipes Executable¶
GenPipes framework can be used to perform various genomic analysis corresponding to the available pipelines. GenPipes is a command line tool. The underlying object-oriented framework is developed in Python. It simplifies the development of new features and its adaptation to new systems; new workflows can be created by implementing a Pipeline object that inherits features and steps from other existing Pipeline objects.
Similarly, deploying GenPipes on a new system may only require the development of the corresponding Scheduler object along with specific configuration files. GenPipes’ command execution details have been implemented using a shared library system, which allows the modification of tasks by simply adjusting input parameters. This simplifies code maintenance and makes changes in software versions consistent across all pipelines.
Running GenPipes¶
Pre-Requisites
Before running GenPipes, you may want to visit the checklist of pre-requisites for GenPipes.
Usage
Here is how you can launch GenPipes. Following is the generic command to run GenPipes:
<pipeline-name>.py -c config -r readset-file -s 1-n -g list-of-commands.txt
bash list-of-commands.txt
where <pipeline-name> refers to one of the available GenPipes Pipelines and step-range-number-1-n refers to the specific steps in the pipeline that need to be executed.
Terminology
In the context of GenPipes, you need to be familiar with the following terms. These constitute inputs and configuration required before you can launch the pipelines.
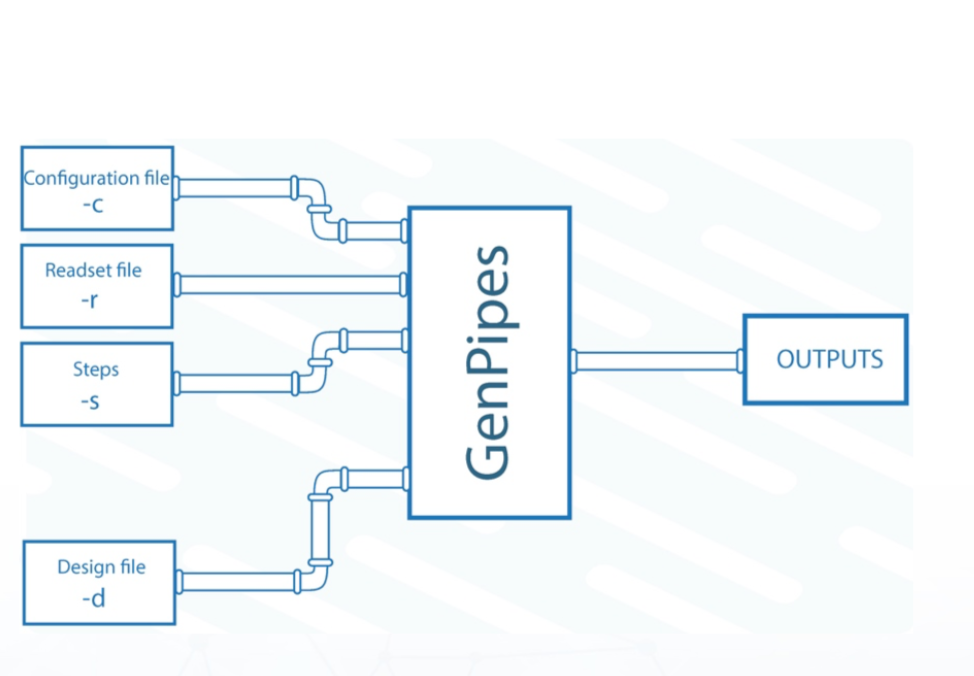
Launching GenPipes
To launch GenPipes, the following is needed:
Name of the pipeline corresponding to one of the available GenPipes Pipelines.
A readset file that contains information about the samples, indicated using the flag “-r”. GenPipes can aggregate and merge samples as indicated by the readset file.
Configuration/ini files that contain parameters related to the cluster and the third-party tools, indicated using the flag “-c”. Configuration files are customizable, allowing users to adjust different parameters.
The specific steps to be executed, indicated by the flag “-s”.
In addition to the configuration files and the input readset file, certain pipelines such as ChIP-Seq and RNA sequencing (RNA-Seq), require a design file that describes each contrast. Custom sample groupings can be defined in the design file. Design files are indicated by the flag “-d”. More information on the design file and the content of each file type can be found in the GenPipes User Guide.
Example Run¶
The following example shows how you can run Hi-C sequencing pipeline using GenPipes installed on Compute Canada data centres. Please ensure you have login access to GenPipes servers. Refer to checklist of pre-requisites for GenPipes before you run this example.
We will now run the pipeline using a test dataset. We will use the first 2 million reads from HIC010 from Rao et al. 2014 (SRR1658581.sra). This is an in-situ Hi-C experiment of GM12878 using MboI restriction enzyme.
You need to first download the test dataset by visiting this link:
In the downloaded zip file, you will find the two fastq read files in folder “rawData” and will find the readset file (readsets.HiC010.tsv) that describes that dataset.
Please ensure you have access to “guillimin” server in Compute Canada data centre. We will run this analysis on guillimin as follows:
hicseq.py -c $MUGQIC_PIPELINES_HOME/pipelines/hicseq/hicseq.base.ini $MUGQIC_PIPELINES_HOME/pipelines/hicseq/hicseq.guillimin.ini -r readsets.HiC010.tsv -s 1-15 -e MboI -g hicseqScript_SRR1658581.txt
To understand what $MUGQIC_PIPELINES_HOME refers to, please see instructions on how to access GenPipes on Compute Canada servers.
In the command above,
-c defines the ini configuration files
-r defines the readset file
-s defines the steps of the pipeline to execute. To check pipeline steps use hicseq -h
-e defines the restriction enzyme used in the HiC library
By default, on Compute Canada servers such as “Cedar”, “Graham” or “Mammouth”, SLURM scheduler is used. On guillimin server, you need to use PBS scheduler. For that you need to specify “-j pbs” option as shown below:
hicseq.py -c $MUGQIC_PIPELINES_HOME/pipelines/hicseq/hicseq.base.ini $MUGQIC_PIPELINES_HOME/pipelines/hicseq/hicseq.guillimn.ini -r readsets.HiC010.tsv -s 1-15 -e MboI -j pbs -g hicseqScript_SRR1658581.txt
The above command generates a list of instructions that need to be executed to run Hi-C sequencing pipeline. These instructions are stored in the file:
hicseqScript_SRR1658581.txt
To execute these instructions, use:
bash hicseqScript_SRR1658581.txt
Warning
You will not see anything happen, but the commands will be sent to the server job queue. So do not run this more than once per job.
To confirm that the commands have been submitted, wait a minute or two depending on the server and type:
showq -u <userID>
where, <userID> is your login id for accessing Compute Canada infrastructure.
In case you ran it several times and launched too many commands you do not want, you can use the following line of code to cancel ALL commands:
showq -u <userID> | tr "|" " "| awk '{print $1}' | xargs -n1 canceljob
Note
Congratulations! You just successfully issued the Hi-C sequencing analysis pipeline commands!!!
After the processing is complete, you can access quality control plots in the homer_tag_directory/HomerQcPlots. You can find the compartment data in the compartments folder, TADs in the TADs folder and significant interactions in the peaks folder.
For more information about output formats please consult the webpage of the third party tool used.
Note
The Hi-C sequencing pipeline also analyzes capture hic data if the “-t capture” flag is used. For more information on the available steps in that pipeline use:
hicseq -h
Example Run with Design File¶
Certain pipelines that involve comparing and contrasting samples, need a Design File. The design file can contain more than one way to contrast and compare samples. To see how this works with GenPipes pipelines, lets run a ChIP-Sequencing experiment.
ChIP-Sequencing Test Dataset
We will use a subset of the ENCODE data. Specifically, the reads that map to chr22 of the following samples ENCFF361CSC and ENCFF837BCE. They represent a ChIP-Seq analysis dataset with the CTCF transcription factor and its control input.
First, you need to download the test dataset from here.
In the downloaded zip file, you will find the two fastq read files in folder rawData and will find the readset file (readsets.chipseqTest.chr22.tsv) that describes that dataset. You will also find the design file (designfile_chipseq.chr22.txt) that contains the contrast of interest.
Following is the content of the Readset file (readsets.chipseqTest.tsv):
Sample Readset Library RunType Run Lane Adapter1 Adapter2 QualityOffset BED FASTQ1 FASTQ2 BAM
ENCFF361CSC_ctrl ENCFF361CSC_chr22 SINGLE_END 2965 1 AGATCGGAAGAGCACACGTCTGAACTCCAGTCA AGATCGGAAGAGCGTCGTGTAGGGAAAGAGTGT 33 rawData/ENCFF361CSC.chr22.fastq
ENCFF837BCE_ctcf ENCFF837BCE_chr22 SINGLE_END 2962 1 AGATCGGAAGAGCACACGTCTGAACTCCAGTCA AGATCGGAAGAGCGTCGTGTAGGGAAAGAGTGT 33 rawData/ENCFF837BCE.chr22.fastq
This analysis contains 2 samples with a single readset each. They are both SINGLE_END runs and have a single fastq file in the “rawData” folder.
Following is the content of the Design file (designfile_chipseq.txt):
Sample CTCF_Input,N
ENCFF361CSC_ctrl 1
ENCFF837BCE_ctcf 2
We see a single analysis CTCF_Input run as Narrow peaks (coded by “N”; you can use “B” for broad peak analysis). This analysis compares CTCF peaks in ENCFF837BCE_ctcf to its input control peaks identified from ENCFF361CSC_ctrl.
Let us now run this ChIP-Sequencing analysis on guillimin server at Compute Canada using the following command:
chipseq.py -c $MUGQIC_PIPELINES_HOME/pipelines/chipseq/chipseq.base.ini $MUGQIC_PIPELINES_HOME/pipelines/chipseq/chipseq.guillimin.ini -r readsets.chipseqTest.chr22.tsv -d designfile_chipseq.chr22.txt -s 1-15 -g chipseqScript.txt
bash chipseqScript.txt
The commands will be sent to the job queue and you will be notified once each step is done. If everything runs smoothly, you should get MUGQICexitStatus:0 or Exit_status=0. If that is not the case, then an error has occurred after which the pipeline usually aborts. To examine the errors, check the content of the job_output folder.
Monitoring GenPipes Pipeline Runs¶
HPC site policies typically limit the number of jobs that a user can submit in a queue. These sites deploy resource schedulers such as Slurm, Moab, PBS and Torque for scheduling and managing sharing of HPC resources.
GenPipes offers a utility script `monitor.sh` to enable better integration with resource schedulers (Slurm, Moab, PBS and Torque) deployed on HPC clusters. It also provides a fail safe mechanism to GenPipes users for re-submitting selected pipeline steps that failed to run due to timeouts. These timeouts are often caused by insufficient resource conditions for jobs running large, complex analysis that need more HPC resources. Another cause of timeouts could be errors in the HPC job queue management system.
The monitoring script lets GenPipes users manage resource constraints in a flexible and robust manner.
Example: Monitoring hicseq.py¶
Here is an example of to use the monitoring script with HiC Sequencing Pipeline:
M_FOLDER=path_to_folder
hicseq.py <options> --genpipes_file hicseq_script.sh
$MUGQIC_PIPELINES_HOME/utils/chunk_genpipes.sh hicseq_script.sh $M_FOLDER
$MUGQIC_PIPELINES_HOME/utils/monitor.sh $M_FOLDER
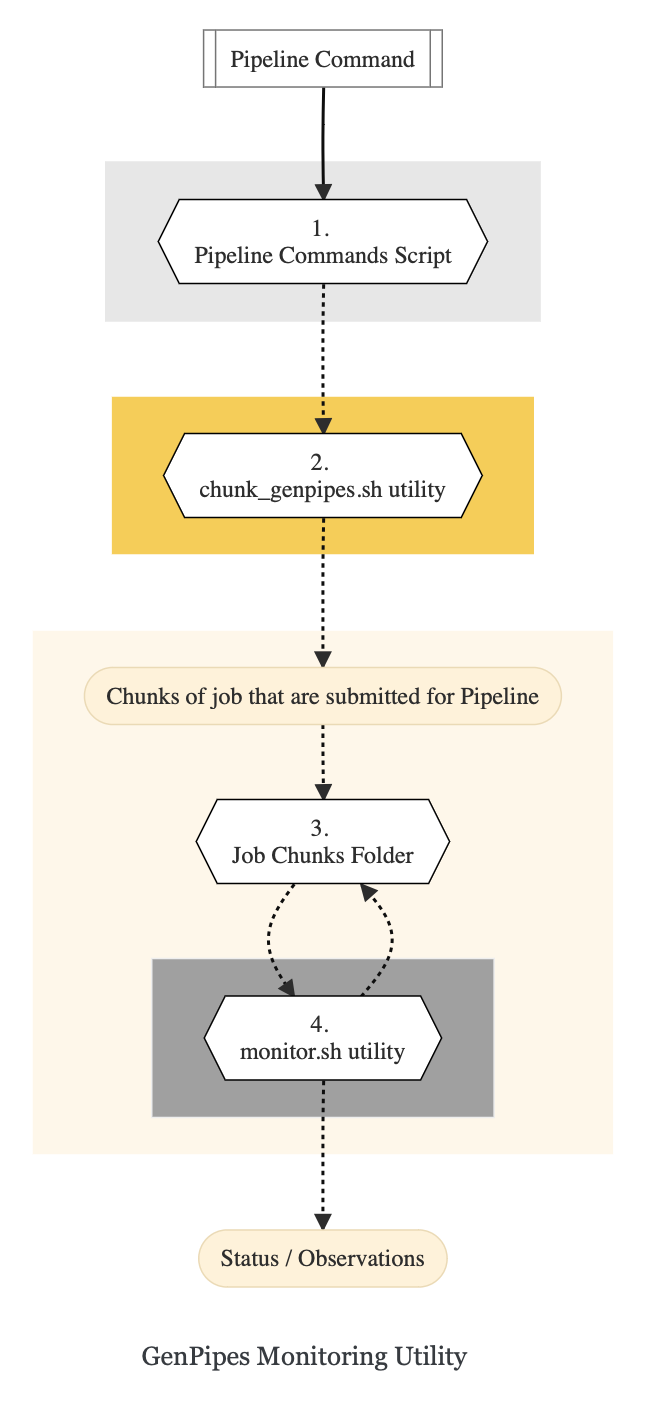
The `chunk_genpipes.sh` script is used to create job chunks of specified size that are submitted at a time. Please note that this script should be executed only once when used in the context of monitoring. The monitor.sh script can be invoked multiple times to check on the status of submitted jobs. The monitor.sh script runs can be canceled or killed by `Ctrl-C` keystroke or disconnecting the ssh shell and restarting monitoring again when required. The monitor.sh script has intelligent lock mechanism to prevent accidentally invoking two monitor.sh script runs in parallel on the on the same folder or GenPipes pipeline run.
Figure below demonstrates how `monitor.sh` utility works. The pipeline command file output is fed into `chunk_genpipes.sh` script which creates the chunks folder as a one time activity. This chunk folder is monitored by the `monitor.sh` script. The monitoring script can be invoked multiple times during the pipeline run. With this script user can monitor the status of the submitted job chunks, whether they have completed successfully or require to be re-submitted.
For a complete list of available GenPipes utilities, refer to the `genpipes/util` folder in the source tree.
Further Information¶
GenPipes pipelines are built around third party tools that the community uses in particular fields. To understand the output of each pipeline, please read the documentation pertaining to the tools that produced the output.
You can see all available GenPipes pipelines for a complete listing of all supported pipelines. To see examples of running other pipelines and also for figuring out how to run pipelines locally or in the cloud on your own GenPipes deployment, refer to GenPipes Tutorials.
For further information or help with particular pipelines, you can send us an email to: